【AI】画像生成AIのStableDiffusionを5分で導入し、AIイラストを実際に生成してみよう。

生成AIが話題の今。
文章を生成するだけでなく画像も生成してみないか?
画像も生成できるようになれば自分がやれることの幅も広がるだろう。
今回はStableDiffusionという画像生成AIを使用する。
おそらく画像生成AIではもっとも有名なAIだろう。
ということで画像生成AIにチャレンジしてみよう。
StableDiffusionとは
入力されたテキストをもとに画像を生成するAIだ。
2022年に登場し、今もなお使われているAIの一つである。
料金は完全無料で、モデルさえあれば簡単に画像を生成できることが利点である。
しかし、自分のPCで動かすためそれなりのスペックが必要だ。
事前準備
Python
今回はPythonが必要になるため事前にPythonを導入しておいてくれ。
上記の記事で説明しているためぜひ読んで導入してみてくれ。
導入済みの方は飛ばしても構わない。
Git
StableDiffusionのインストールにはgitコマンドも含まれているため事前にインストールしておく。
上記の記事で説明しているためぜひ読んで導入してみてくれ。
導入済みの方は飛ばしても構わない。
導入方法
StableDiffusionのダウンロード
AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI (github.com)
上記のサイトからStableDiffusionを入手する。
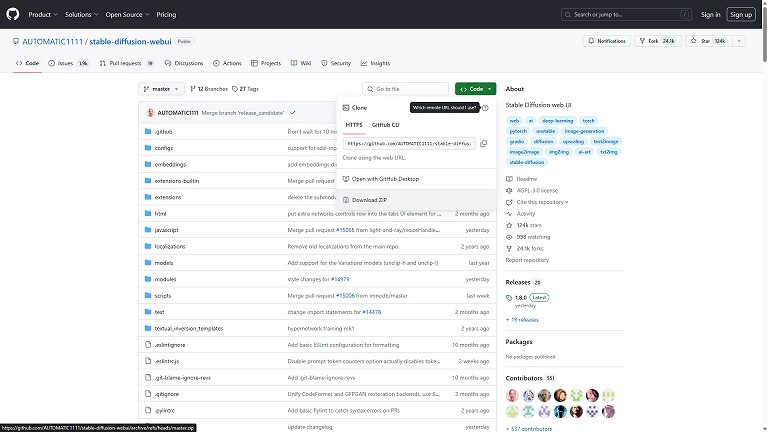
緑色の<>codeを選択し、Download ZIPを選択する。

ダウンロードした、stable-diffusion-webui-master.zipを展開する。
これでStableDiffusionの準備は完了。
生成用モデルのダウンロード
デフォルトのモデルは低品質なので、事前にモデルをダウンロードする必要がある。
モデルの容量は最低でも1GB以上なのでストレージを空けておく。
高品質になればなるほど容量は大きくなり10GBくらいのモデルもある。
以下おすすめモデルを簡単に紹介するのでどれか一つをダウンロード。
Anything V5
Anything | 万象熔炉 – V5.0 | Stable Diffusion Checkpoint | Civitai
定番のモデルといえばAnythingである。
特徴は、短い命令文で高品質な画像を生成できる。
Anime Pastel Dream
Anime Pastel Dream – Soft – baked vae | Stable Diffusion Checkpoint | Civitai
アニメ系等のモデルである。
特徴は、アニメ調の人物を生成し、喜怒哀楽まで表現できる。
Beautiful Realistic Asians V7
Beautiful Realistic Asians – v7 | Stable Diffusion Checkpoint | Civitai
アジア人のような顔立ちのモデルである。
特徴は、アジア人をモデルとした人物を生成できる。
生成用モデルのインストール
今回はAnyhing V5をダウンロードしたためanything_v50.safetensorsというファイルを使用する。
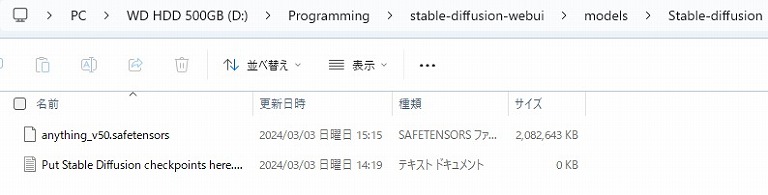
\stable-diffusion-webui\models\Stable-diffusionモデルは\stable-diffusion-webui\models\Stable-diffusionに格納する。
これでモデルのインストールは完了だ。
StableDiffusionにxformersを導入
xformersを導入すると、高速で画像を生成できる。
導入しておいて損はないだろう。
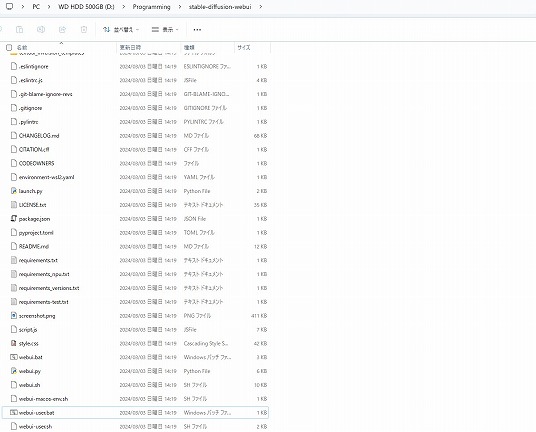
\stable-diffusion-webui\webui-user.bat\stable-diffusion-webuiの中にあるwebui-user.batを右クリックする。
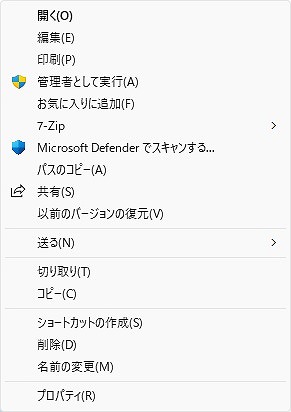
編集(E)を選択する。
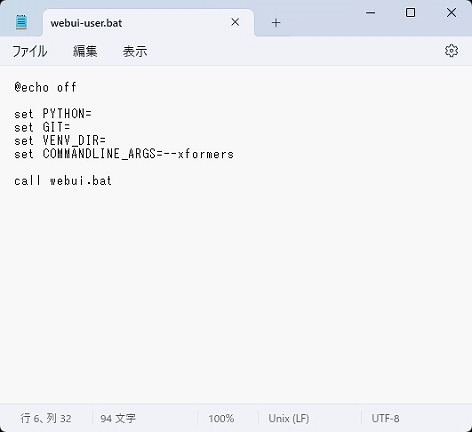
set COMMANDLINE_ARGS=--xformersコマンドラインにxformersを入力することによって適応される。
StableDiffusionをインストール
webui-user.batをダブルクリックする。
するとインストールが開始される。
5分くらいかかるので気長に待つべし。
インストールが完了すると、Running on local URLと表示される。
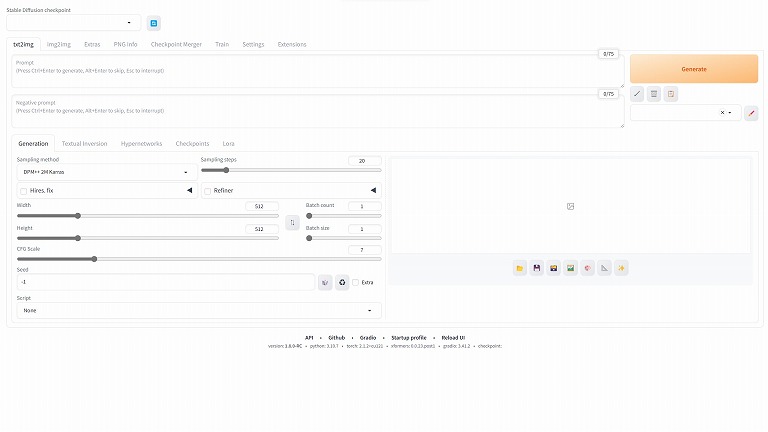
すると自動的にサイトが立ち上がる。
これでインストールは完了。
StableDiffusionの使い方
Stable Diffusion checkpoint
使用したいモデルを選択する。

今回は、ダウンロードしたAnyhing V5を使用する。
プルダウンメニュー形式なので、複数格納しておけば様々なモデルが使用できる。
Prompt

生成したい特徴を入力する。

girl例えば、女の子を生成したい場合は、girlと入力する。

girl, police複数入力したい場合は「,(コンマ)」で区切る。

実際に生成してみるとこのような感じの画像が出力される。
簡単だね。
注意点として、英語で入力しないと認識しない。
Negative prompt

生成して欲しくない特徴を入力する。

building例えば、建物を表示して欲しくない場合は、buildingと入力する。

すると背景が表示されなくなる。
簡単だね。
注意点として、こちらも英語で入力しないと認識しない。
Generate

Generateボタンを選択すれば画像が生成される。

先ほど設定したプロンプト通りに画像が生成されれば成功だ。
まとめ
Stable Diffusionの使い方は理解できただろうか。
初めて画像生成AIを使ってみたが、すごい高精度で驚いた。
2022年に出たばかりでこの精度は素晴らしい。
今後も期待できる生成AIコンテンツの一つであろう。
この記事が参考になってくれたら幸いだ。





コメントはこちらから