【プログラミング】超簡単にYahooニュースをスクレイピングし、最新のニュースを取得してみよう。

スクレイピング技術というのは非常に多くのところで活用されている。
この技術を私用すれば、そのページを直接確認せずとも情報が取得できる。
そんな近未来的要素を試すべく、今回はYahooニュースをスクレイピングして最新のニュースを取得する方法を紹介する。
スクレイピングとは
スクレイピングとは、ウェブサイトから情報を自動的に抽出する手法だ。
プログラムを使ってウェブページを読み込み、HTMLの構造を解析して必要なデータを取得することを指す。
これにより、大量のデータを手動でコピーすることなく効率的に収集できる。
サンプルコード
スクリプトファイルの用意
まずは、Pythonのファイルを用意する。
今回は、GPIOの接続を判定するPythonスクリプトを用意する。
app.py
#app.pyapp.pyはスクレイピングを行うPythonスクリプトだ。
ディレクトリ構造をツリーで確認
project_directory/ # プロジェクトのルートフォルダ
└── app.pyファイルは上記のディレクトリ構造で配置する。
これで準備は完了だ。
Yahooニュースをスクレイピングするコード
import re
import requests
from bs4 import BeautifulSoup
url = "https://news.yahoo.co.jp/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
# 主要ニュースのリストを取得
# その1:URLベースの抽出方法
pickups = soup.find_all(href=re.compile("https://news.yahoo.co.jp/pickup"))
# その2:クラス名ベースの抽出方法
# pickups = soup.select("a.sc-1nhdoj2-1")
for i in pickups:
print(i.text)コードの説明
モジュールの読み込み
import re
import requests
from bs4 import BeautifulSoupreは、正規表現を使用するための標準ライブラリだ。
requestsは、ウェブページのHTMLを取得するためのライブラリだ。
BeautifulSoupは、HTMLデータを解析し、特定の要素を抽出するためのライブラリだ。
URLとヘッダーの設定
url = "https://news.yahoo.co.jp/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)urlは、スクレイピング対象のURLを指定する。
headers:User-Agentを指定することで、ブラウザからのアクセスを装ったリクエストを送信する。これにより、Bot対策でブロックされるのを防ぐ。
response:requests.get()を使用して指定したURLのHTMLデータを取得する。
HTMLの解析
soup = BeautifulSoup(response.text, 'html.parser')BeautifulSoup()を使って、取得したHTMLデータ (response.text) を解析する。
主要ニュースの抽出
その1:URLベースの抽出方法
# その1:URLベースの抽出方法
pickups = soup.find_all(href=re.compile("https://news.yahoo.co.jp/pickup")).find_all():HTMLから指定した条件に合うすべての要素を取得する。
re.compile()で正規表現を用いて、URLにhttps://news.yahoo.co.jp/pickupが含まれるリンクだけを抽出する。
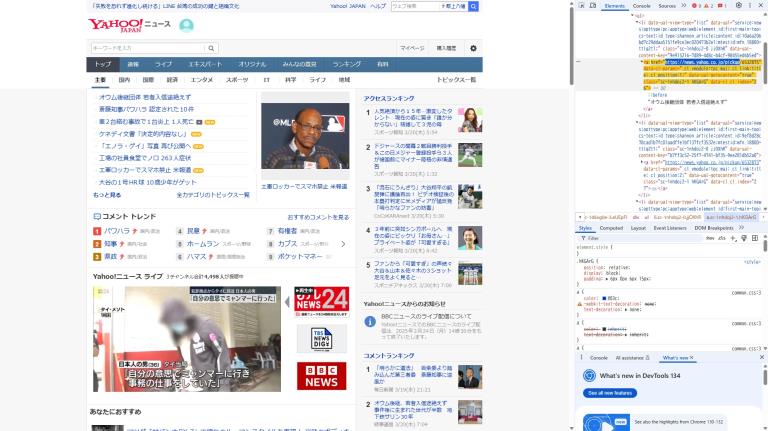
その1では、aタグのリンクに含まれているURLを指定することでニュースのみを特定している。
その2:クラス名ベースの抽出方法
# その2:クラス名ベースの抽出方法
# pickups = soup.select("a.sc-1nhdoj2-1").select()は、CSSセレクタを使用して要素を選択する。
a.sc-1nhdoj2-1は、主要ニュースリンクのクラス名を指定する。
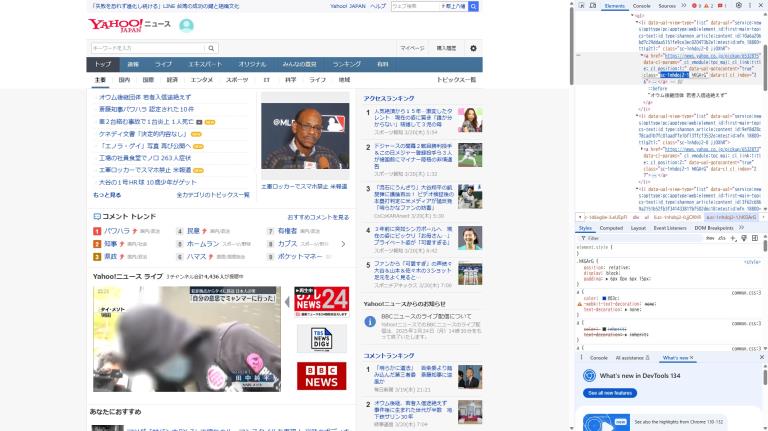
その2では、classを指定することで、ニュースのみを特定している。
ニュースのタイトルを表示
for i in pickups:
print(i.text)forループでpickupsの要素を1つずつ取り出す。
.textでリンクのテキスト(=ニュースの見出し)を取得し、表示している。
出力結果 (例)
オウム後継団体 若者入信途絶えず
斎藤知事パワハラ 認定された10件
車2台絡む事故で1台炎上 1人死亡
ケネディ文書「決定的内容なし」
「エノラ・ゲイ」写真 再び公開へ
工場の社員食堂でノロ 263人症状
エ軍ロッカーでスマホ禁止 米報道
大谷の1号HR球 10歳少年がゲット
エ軍ロッカーでスマホ禁止 米報道ソースコードのダウンロード
これらのコードはGithubにアップロードしている。
上記のページに、すべてアップロードされているので、必要な方はぜひ使ってみてくれ。
まとめ
いかがだっただろうか。
無事にYahooニュースのスクレイピングは出来ただろうか。
スクレイピング方法さえ分かればどのサイトでも応用可能だ。
ぜひ使ってみてくれ。





コメントはこちらから